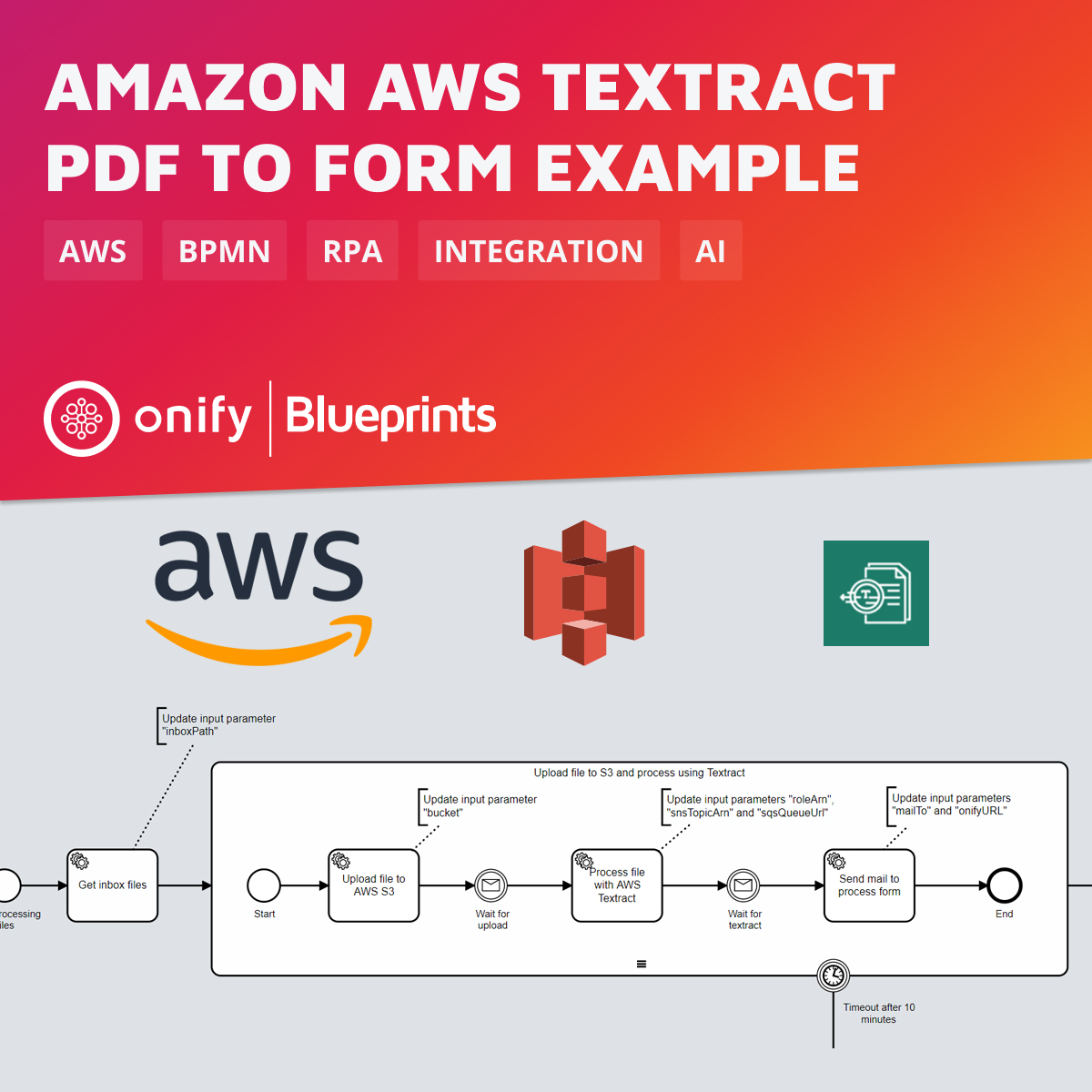
Amazon Textract ist ein maschineller Lerndienst von AWS, der automatisch Text, Handschrift und Daten aus gescannten Dokumenten extrahiert. Textract bietet nicht nur eine einfache optische Zeichenerkennung (OCR), sondern geht einen Schritt weiter, indem es Informationen aus komplexen Strukturen wie Formularen und Tabellen identifiziert, versteht und extrahiert. Dies erleichtert den Anwendern die Umwandlung herkömmlicher Papierdokumente in verwertbare digitale Daten, wodurch Prozesse gestrafft und die manuelle Dateneingabe reduziert werden.
In diesem Onify Blueprint zeigen wir, wie man 1) Dateien in AWS S3 hochlädt, 2) das PDF mit AWS Textract verarbeitet und 3) einen Link zu einem Formular sendet, um die Daten aus dem PDF zu überprüfen. Der nächste Schritt, die Entscheidung, wohin die Daten aus dem Formular gesendet werden sollen, wird in einem anderen Blueprint behandelt 🙂.
Weitere Informationen zu diesem Thema finden Sie unter Blueprint. GitHub.