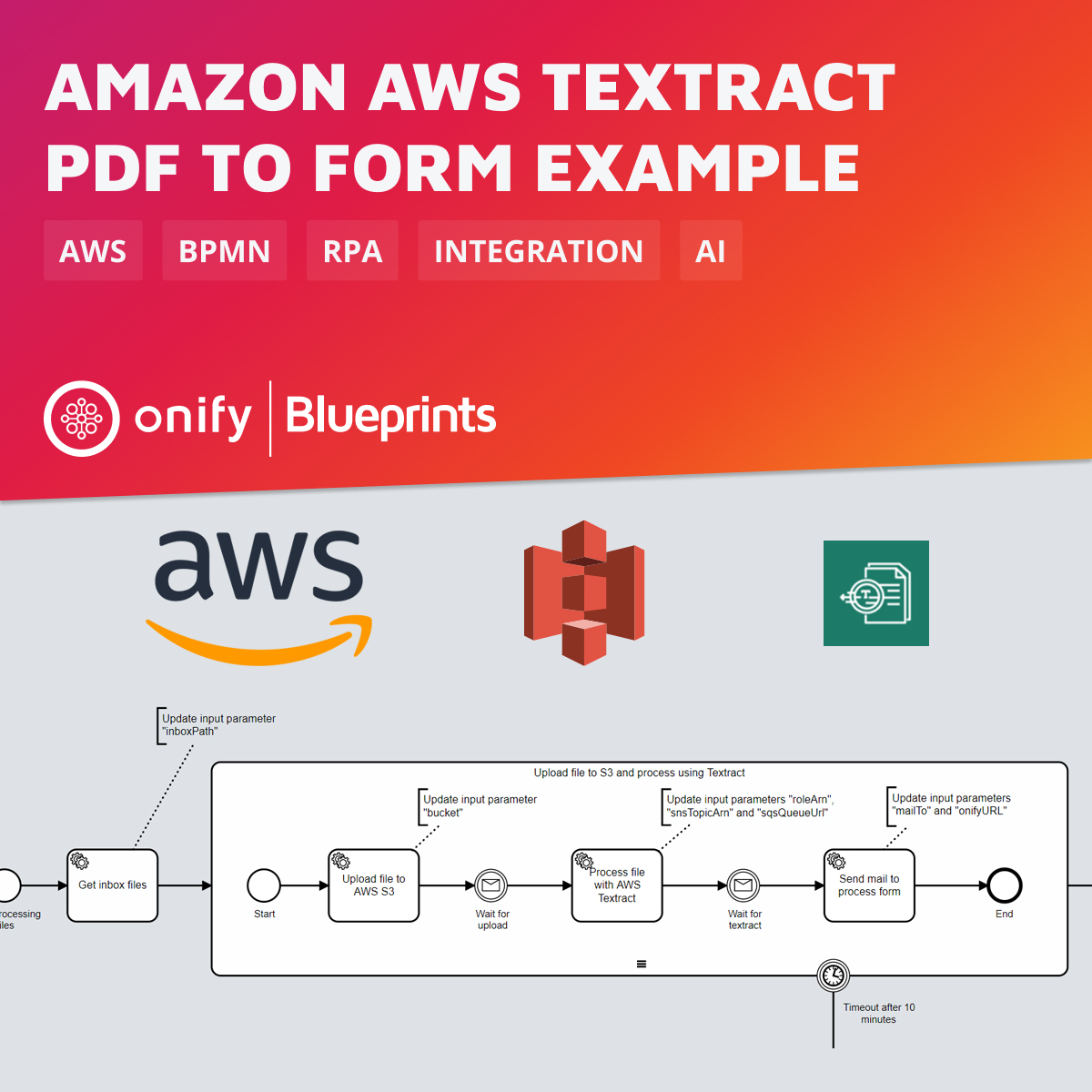
Amazon Textract er en maskinlæringstjeneste fra AWS som automatisk trekker ut tekst, håndskrift og data fra skannede dokumenter. I stedet for bare å tilby grunnleggende optisk tegngjenkjenning (OCR), går Textract et skritt videre ved å identifisere, forstå og trekke ut informasjon fra komplekse strukturer som skjemaer og tabeller. Dette gjør det enklere for brukerne å forvandle tradisjonelle papirdokumenter til brukbare digitale data, noe som effektiviserer prosesser og reduserer behovet for manuell dataregistrering.
I denne Onify Blueprint viser vi hvordan man 1) laster opp filer til AWS S3, 2) behandler PDF-filen ved hjelp av AWS Textract og 3) sender en lenke til et skjema for å verifisere dataene fra PDF-filen. Det neste trinnet, å bestemme hvor dataene fra skjemaet skal sendes, håndteres i en annen Blueprint 🙂.
For mer informasjon om dette Blueprint, besøk GitHub.