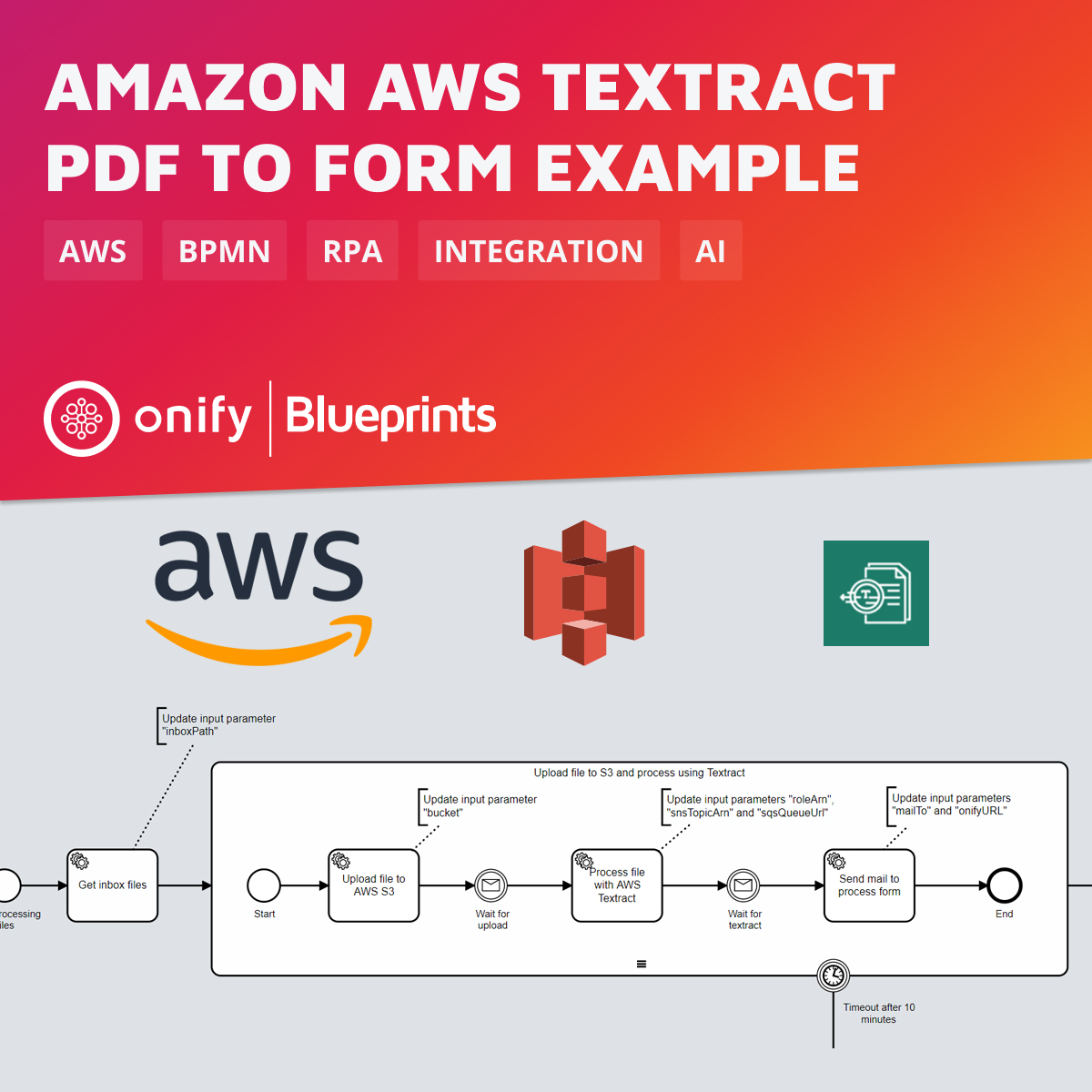
Amazon Textract är en maskininlärningstjänst från AWS som automatiskt extraherar text, handskrift och data från skannade dokument. Istället för att bara erbjuda grundläggande optisk teckenigenkänning (OCR), går Textract ett steg längre genom att identifiera, förstå och extrahera information från komplexa strukturer som formulär och tabeller. Detta gör det enklare för användare att omvandla traditionella pappersdokument till användbar digital data, vilket effektiviserar processer och minskar manuell datainmatning.
I denna Onify Blueprint visar vi hur man kan 1) ladda upp filer till AWS S3, 2) bearbeta PDF-filen med hjälp av AWS Textract och 3) skicka en länk till ett formulär för att verifiera data från PDF:en. Nästa steg, att bestämma vart data från formuläret ska skickas, hanteras i en annan Blueprint 🙂
För mer info om denna Blueprint, besök GitHub.